
复旦×创智OpenMOSS团队 投稿
量子位 | 公众号 QbitAI
被CVPR 2026收录!
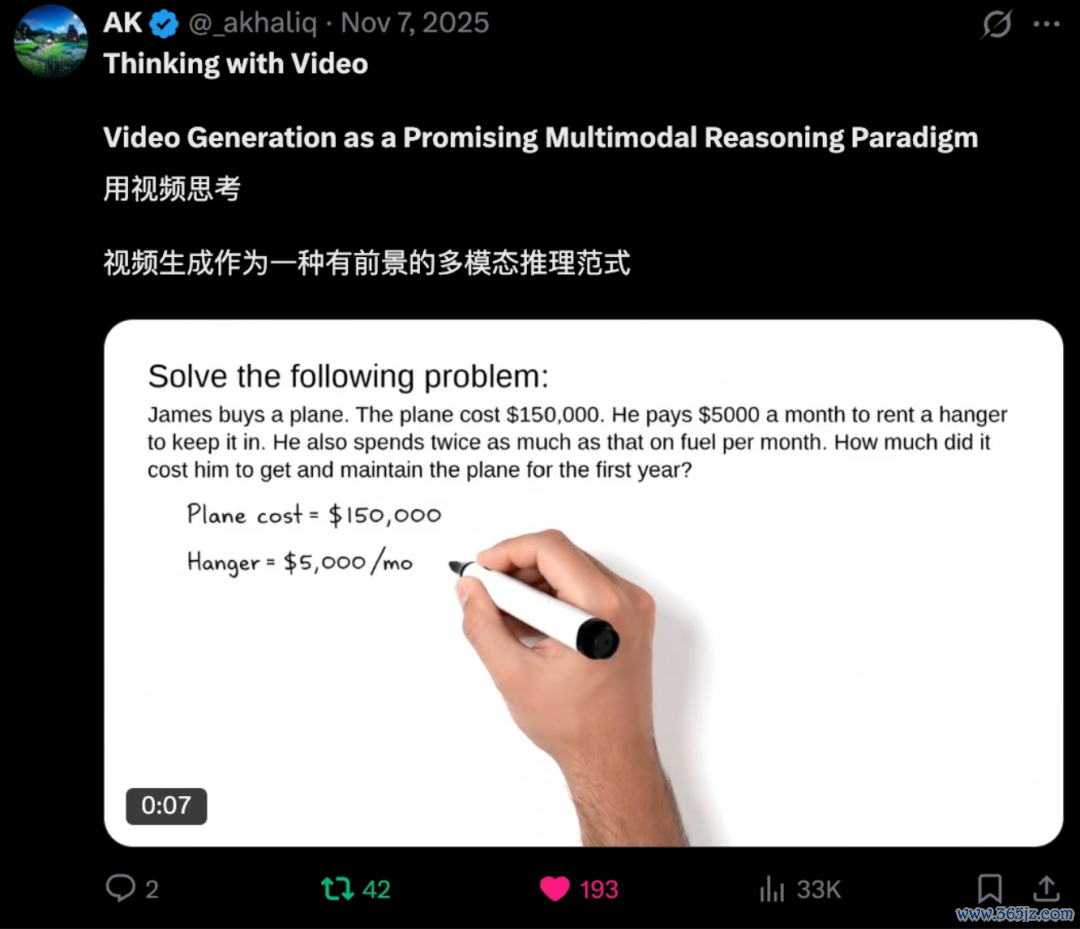
复旦邱锡鹏团队(OpenMOSS)初次提议Thinking with Video这一推理新范式:
借助视频生成模子,以视频帧为和解绪论进行多模态推理,冲破视觉与文本的范围。

团队发现,Thinking with Text(基于文本的CoT推理)和Thinking with Images(在CoT中加上图像援助推理)范式已大幅升迁了LLMs和VLMs的推理才气。
但它们仍有局限:静态图像无法展现动态经过,文本与视觉模态的割裂阻隔了和解交融与生成。
而借助新范式Thinking with Video,视频生成模子在视觉任务上不仅总体比好意思SOTA VLMs,而况竟也能科罚MATH、MMMU等文本推理任务。
这可谓提前预判了前不久谷歌Gemini Omni曝光的“造就黑板推公式”的文本推理才气。
当今该责任在外交平台X上受到存眷,数据和代码已全面开源。
Thinking with Video:视频生成行为多模态推理新范式
从Thinking with Text到Thinking with Images,这些推理范式仍存在紧要残障:
1、静态敛迹:图像只可捕捉单一技巧的信息,难以抒发动态经过、时候变化与连气儿变换。
2、模态分离:文本与视觉仍被分开处理,短少一种当然和解二者的推理载体。
盘考团队提神到,视频生成模子能像东谈主不异进行绘制、思象、模拟,有助于科罚视觉推理问题。
同期,视频帧还可承载文本,从而也有望完成文本推理问题。
由此可见,Thinking with Video自然领有多模态推理上风,盘考团队对此进行了深切探索。
VideoThinkBench:详细的视频生成推理测试基准
为了全面评估视频生成模子的推理才气,盘考团队构建了VideoThinkBench,共包含4149个测试样本,分为视觉任务和文本任务(图1)。
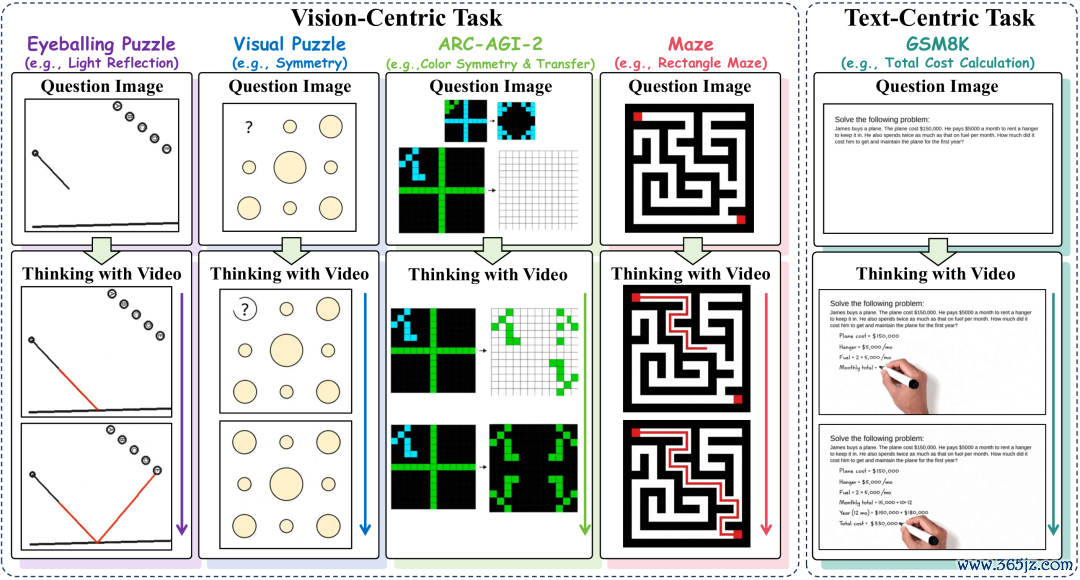
△图1:VideoThinkBench的任务和Thinking with Video经过
视觉任务磨砺几何直观、视觉形式归纳、抽象章程归纳、空间计较与搜索,包括Eyeballing Puzzles、Visual Puzzles、ARC-AGI-2和Mazes。
这些视觉任务的样本通过圭表自动化生成,并配有可考据谜底,便于对视频扫尾进行精确评测。
文本任务则由已有基准(如MATH、MMLU、MathVista、MMMU)改编而来,包含纯文本和多模态的数学推理与通用推理。
作家在VideoThinkBench上对视频生成模子(如Sora-2、Veo 3.1)进行了评测,并将其扫尾与三个SOTA VLM(Gemini 2.5 Pro、GPT-5 high、Claude Sonnet 4.5)进行了对比,扫尾出东谈主预感。
中枢发现一:Thinking with Video让模子匹敌致使卓著顶尖VLM
盘考发现,视频生成模子在视觉任务上有出色发挥,总体可比好意思SOTA VLM(表1)。
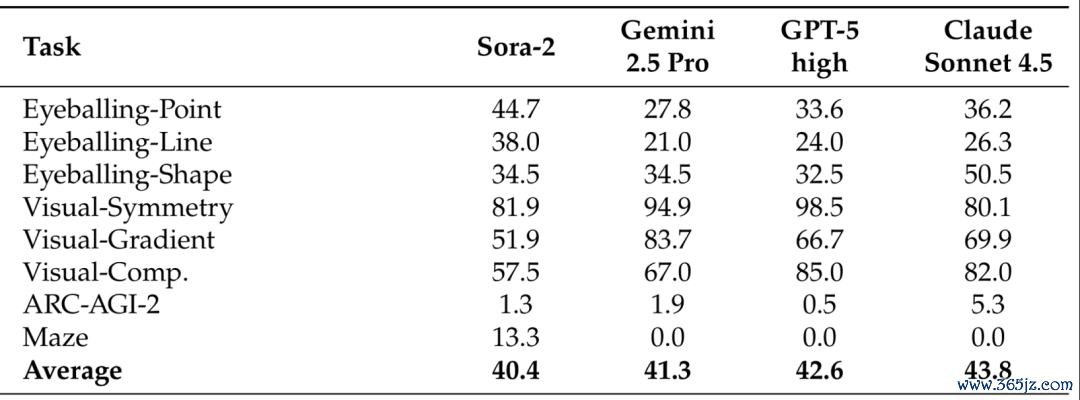
△表1:视觉任务上的发挥,Sora-2竟能匹敌三个顶尖VLM
Thinking with Video能科罚几何直观推理、视觉归纳推理,致使ARC-AGI-2等各样的视觉任务。
Eyeballing Puzzles:绘制模拟,几何推理卓著顶尖VLM

△图2:Eyeballing Puzzles任务的输入输出示例
Eyeballing Puzzles(目测谜题)分为Point / Line / Shape三种类型(图2)。
施行标明,Sora-2可在视频中模拟色泽的延长和反射,并主管几何元素(举例点和线)来援助推理(图3)。
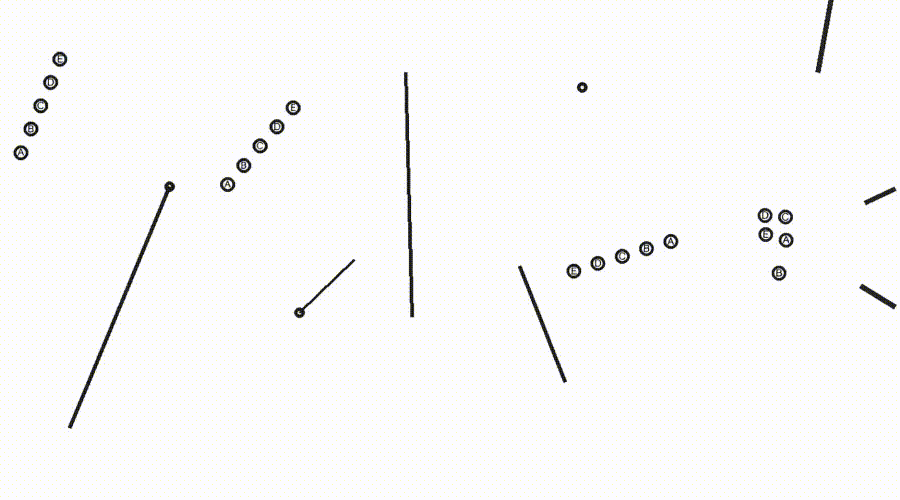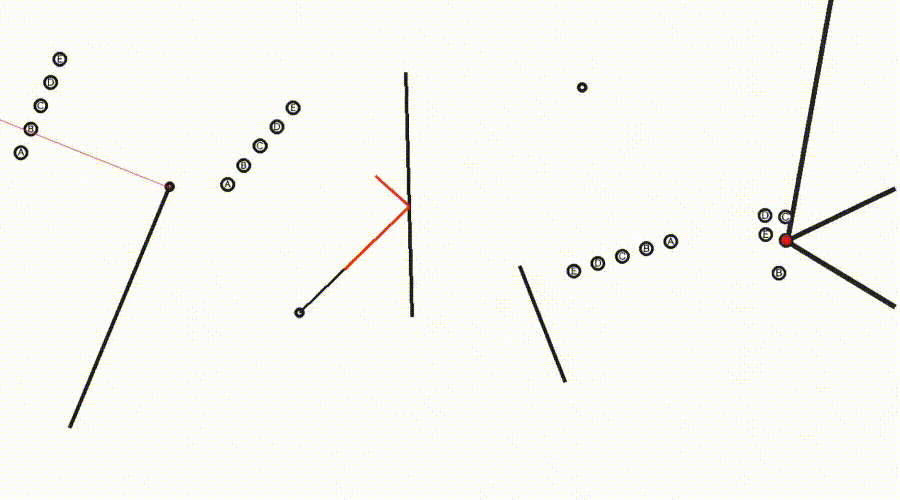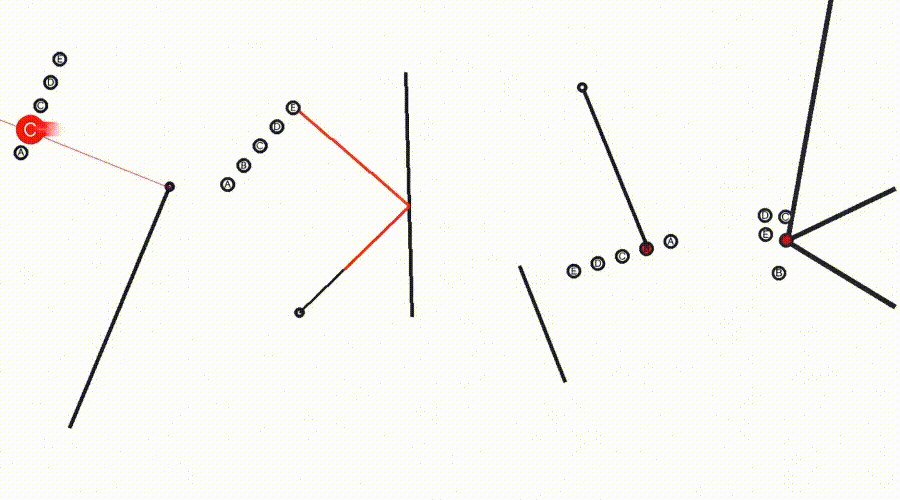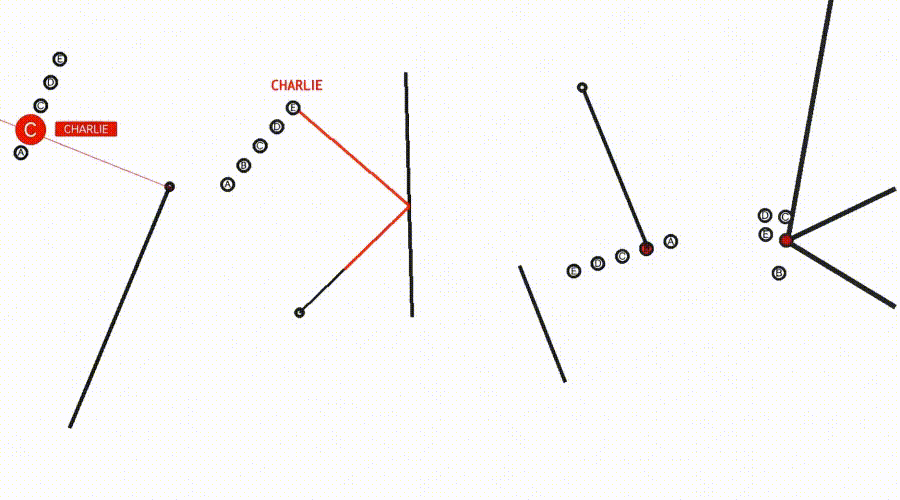
△图3:Sora-2生成视频科罚Eyeballing Puzzles,临了模子会将其谜底选项标红,并在语音中说出谜底
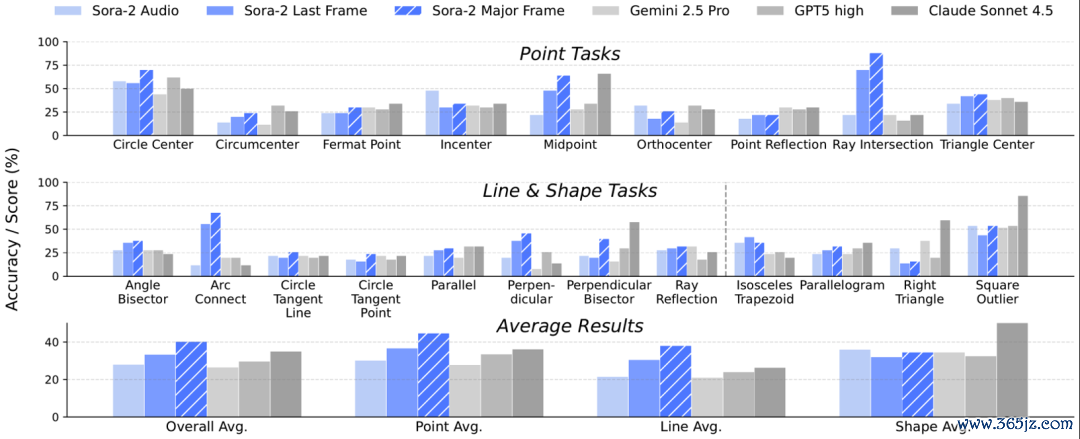
△图4:各模子在Eyeballing Puzzles上的发挥
在多帧投票评估下(期骗扫数视频经过,幸免临了一帧噪声),Sora-2的总体发挥竟打败了三个SOTA VLM(图4),充分展现了Thinking with Video能进行绘制模拟的独有上风。
Visual Puzzles:视频生成能完成归纳推理
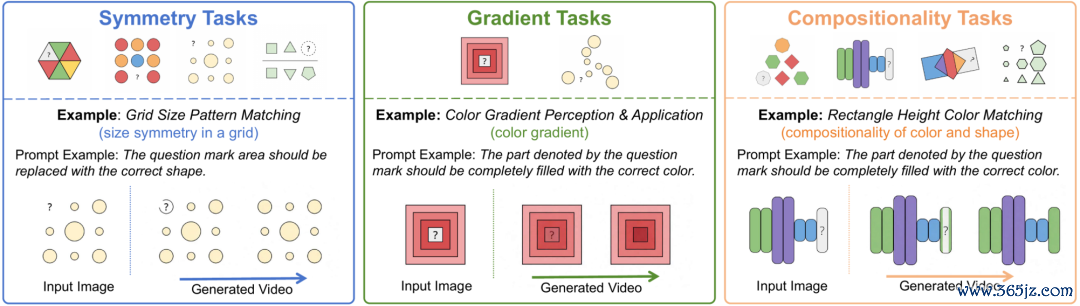
△图5:Visual Puzzles任务的输入输出示例
Visual Puzzles磨砺模子凭据心扉、阵势、尺寸进行归纳推理(图5)。
问题不给选项,径直生成视频来补全缺失的心扉或阵势(图6)。
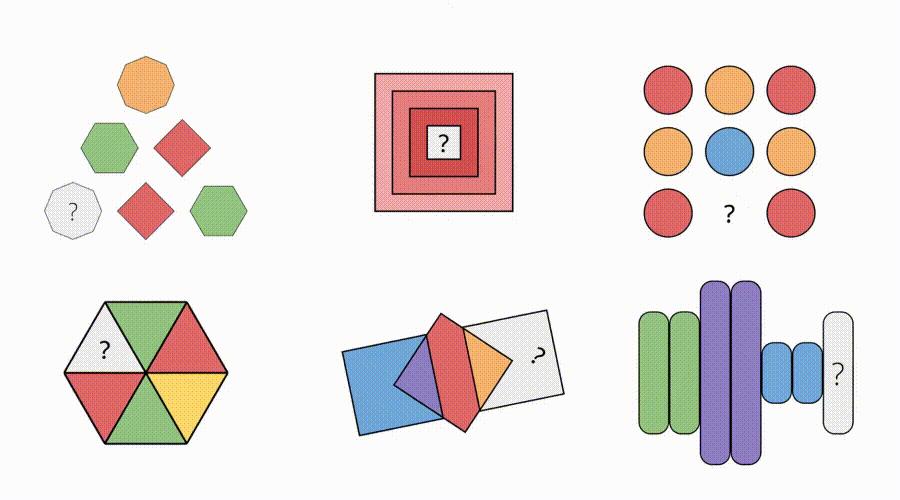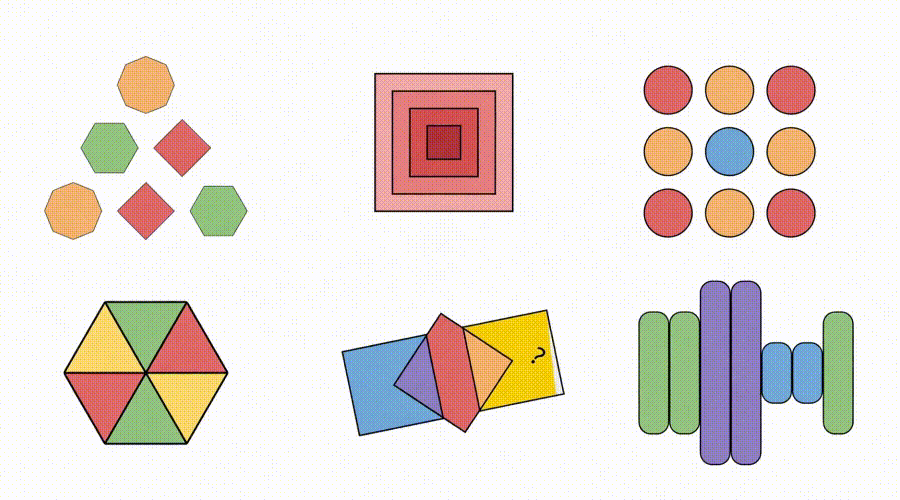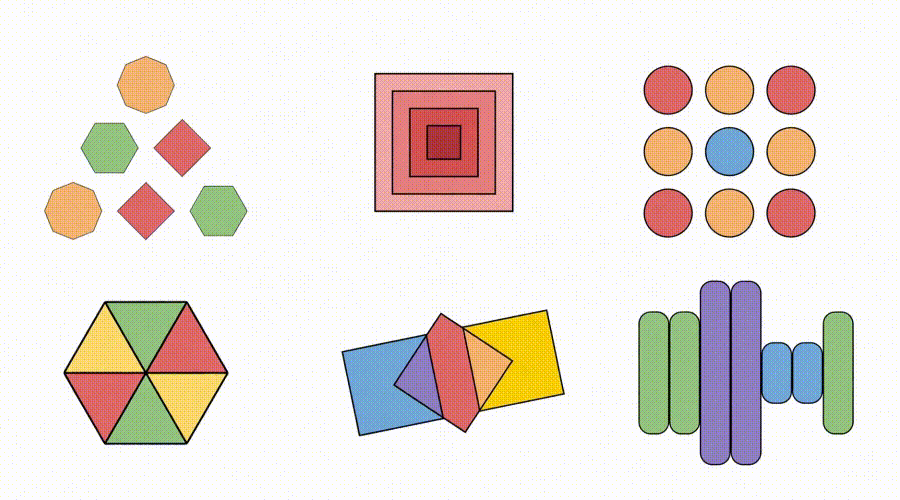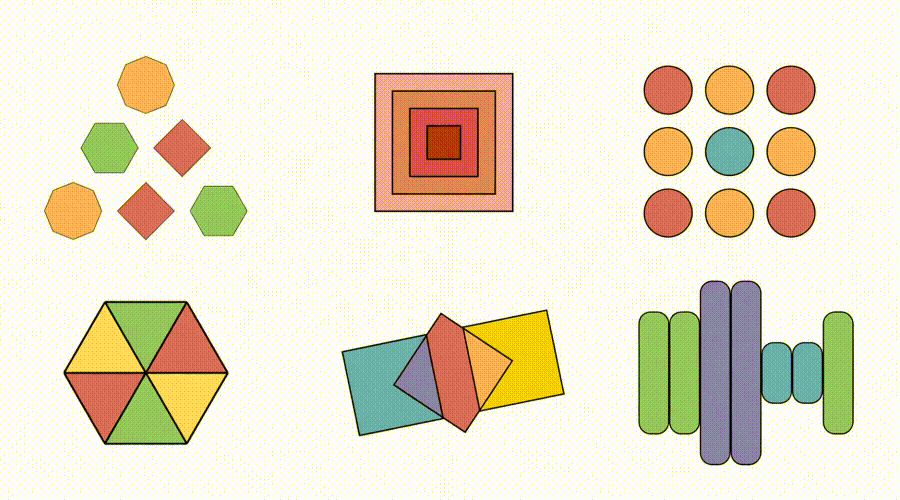
△图6:Sora-2生成视频科罚各样的Visual Puzzles
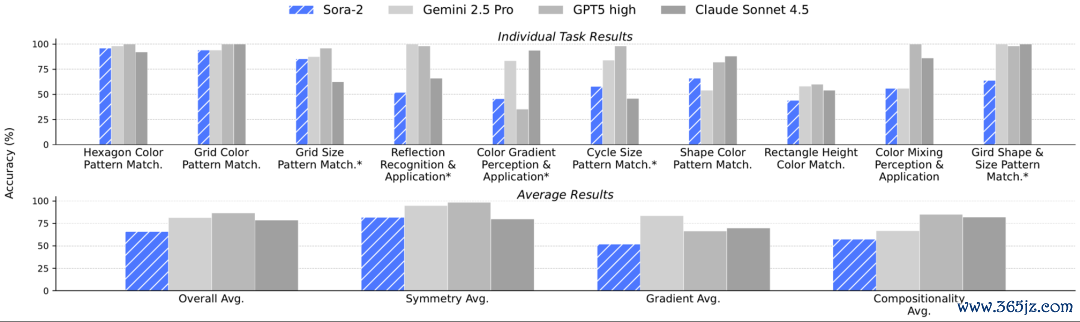
△图7:各模子在Visual Puzzles上的发挥
在这些视觉谜题上,Sora-2也发挥优秀,并在对称任务(Symmetry)中打败了Claude Sonnet 4.5(图7)。
可见视频生成模子不仅能画线模拟,还能从视觉结构中归纳和应用程序。
ARC-AGI-2:视频生成模子是Few-shot Learner
ARC-AGI-2面向更抽象的章程归纳才气,模子需要不雅察多少输入-输出示例,揣度视觉变换章程,再将章程应用到新的网格中。
施行发现,在这一更有挑战性的任务上,Sora-2也能凭据示例作念出正确瞻望(图8),展现了从示例中学习变换章程的才气。

△图8:以视频生成科罚ARC-AGI-2的题目

△表2:和解视觉输入下各模子在ARC-AGI-2上的发挥
在相易的视觉输入阵势下,JRS直播2026世界杯比赛直播顶尖VLM在ARC-AGI-2上发挥欠佳,而Sora-2已可与之匹敌。
由此可见,视频生成模子也能成为Few-shot Learner。
进一步施行袒露,加多示例还能升迁视频生成模子的发挥。
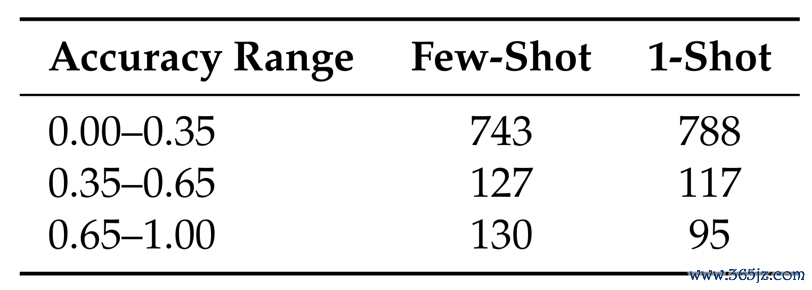
△表3:提供多个和一个示例下的Sora-2的发挥
比拟只提供一个示例(1-Shot),提供更多示例(Few-Shot)后,更多测试样本达到较高的像素级准确率,也便是更接近正确谜底(表3)。
这一发现标明,视频生成模子的In-Context Learning值得进一步探索。
中枢发现二:视频生成模子竟能进行文本推理
视频生成模子也能科罚文本推理问题吗?
这让东谈主思到不久前曝光的Gemini Omni,网友用它生成了一个在黑板上推导公式的视频,后果号称惊艳。
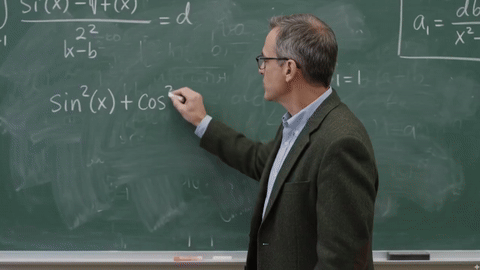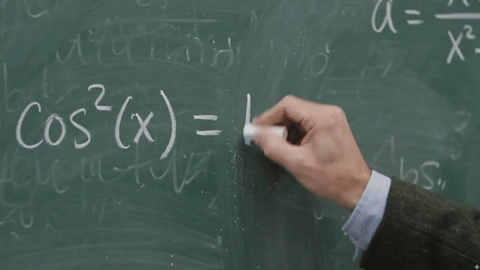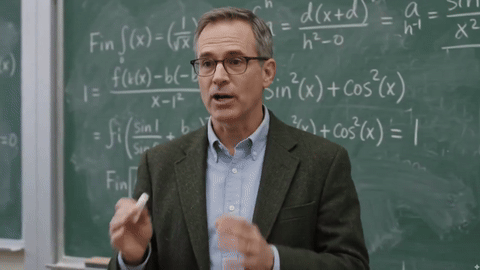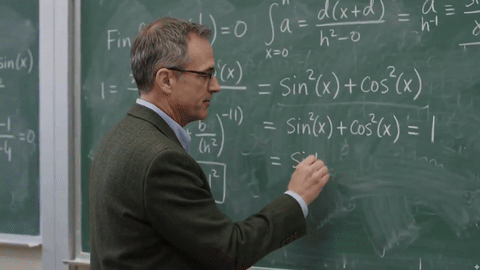
△图9:Gemini Omni生成的公式推导视频,来自𝕏@Chetasluah
关系词,盘考团队在此之前就提议了让视频生成模子科罚文本推理任务,并进行了系统性的评测。
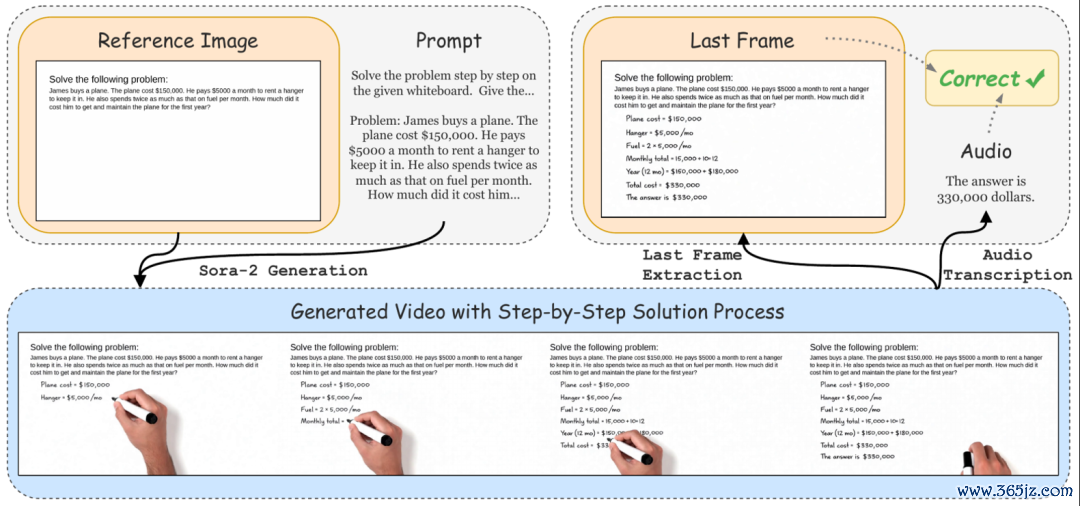
△图10:文本任务的输入和输出以及评测姿色
VideoThinkBench中的文本任务的输入由文本领导词和参考图像构成(图10)。
问题写在领导词中,也展示在参考图像里。
模子需要生成一段视频,在视频中写出解题经过(图11),并在语音中也说出最终谜底。
评测时,大模子基于圭表谜底,别离判断临了一帧和语音中的谜底是否正确。

△图11:在视频生成中科罚GSM8K的题目
扫尾出东谈主预感:
如表4,Sora-2在多个文本测试集上获得亮眼发挥,比如在MATH上准确率达 92%,在MMMU上达到69.2%,尽管在更难的文本任务上离顶尖VLM有较大差距。
这一扫尾标明,视频生成模子很有后劲通过在视频帧中镶嵌文原来进行文本推理。
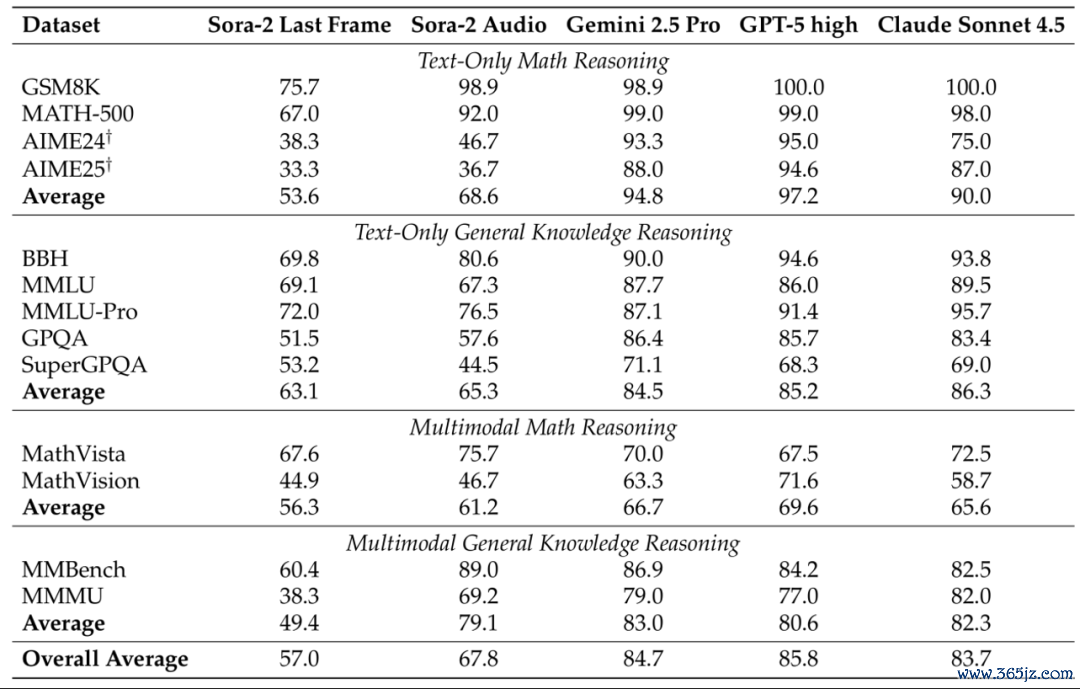
△表4:文本任务评测扫尾
盘考团队还进一步分析了文本任务发挥是否是着手于测试集知道。
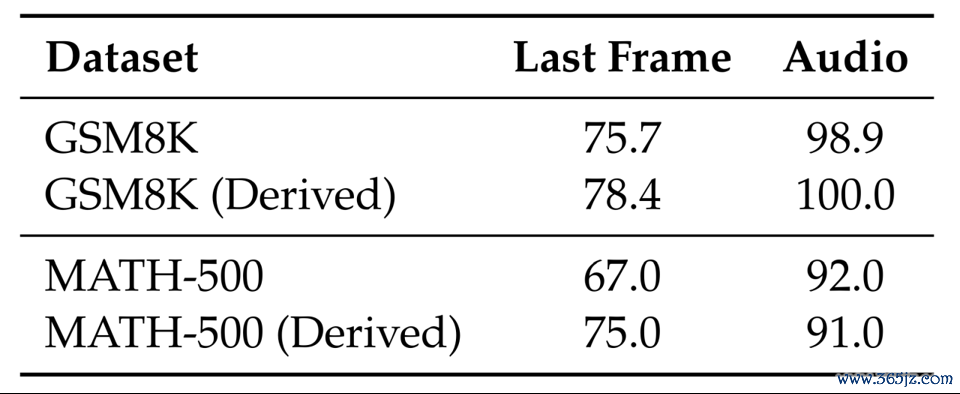
△表5:在原始和改编的文本题目上的发挥
改编测试数据(GSM8K与MATH),修改问题中的数值和表述进行再行测试后,团队发现Sora-2的发挥并未出现下落(表5)。
阐述其才气并非来自测试集记忆,而是文本任务上具有信得过后劲。
虽然,东谈主工案例分析发现视频中的书写经过巧合明晰可靠。
如图12,仅有13.91%的解答视频中语本经过透澈正确,快要一半的经过齐是无法阅读或失实的。
由此可见,模子会给出正确谜底,但难以生成明晰、牢固和透澈正确的推理设施。

△图12:对Sora-2文本作答经过的分析
盘考还分析了视频生成模子的文本才气,是否可能着手于一个前置的领导词改写模子。
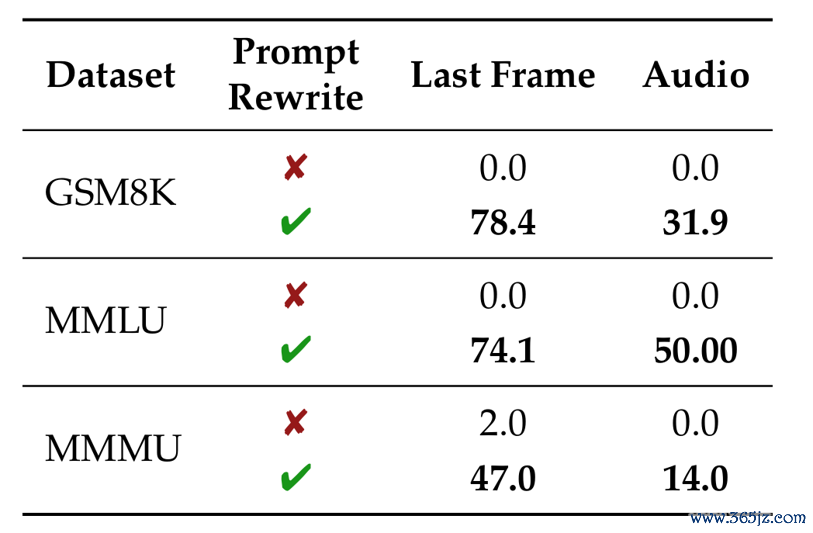
△表6:Wan 2.5在有/无领导词改写下的发挥
Wan 2.5的API可遗弃是否允许改写领导词。
在关闭领导词改写后,Wan 2.5在文本任务上的发挥险些降为零(表6)。
由此可见,若有领导词改写模块,则其可能在最终视频生成前就将文本题目解出。
视频生成推理的Test Time Scaling可能成为新的盘考前沿
在LLM推理中,经典的Test Time Scaling方法如Self-Consistency通过屡次采样和大齐投票升迁准确率。
盘考团队发现,Thinking with Video竟也有雷同的论断。
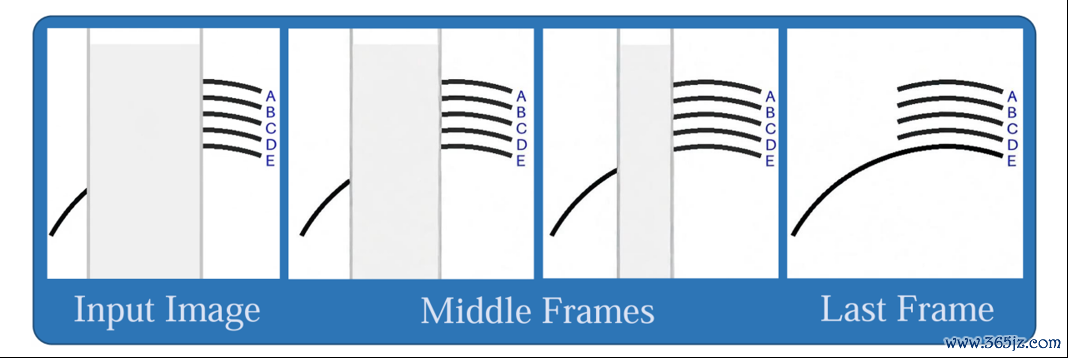
△图13:通过视频生成科罚Arc Connect问题
在Eyeballing Puzzle的任务(Arc Connect,图13)中,只看单次生成的临了一帧,准确率为56%;改用多帧大齐投票后升迁到68%。
进一步,若让Sora-2生成5次视频并对扫尾投票,多帧大齐投票准确率可径直升迁至90%(表7)。

△表7:采样多个视频进行投票的扫尾
由此可见,Self-consistency芜俚升迁视频生成模子在视觉任务上的发挥。
因此视频生成模子的Test Time Scaling也将成为新的盘考前沿。
小结一下
盘考初次提议了Thinking with Video这一多模态推理新范式:
基于视频生成模子,以视频帧为和解绪论进行多模态推理。
在作家筹划的VideoThinkBench上,视频生成模子展现出不凡推理才气。
期骗绘画与思象的上风,Sora-2在视觉任务上可比好意思顶尖VLM,此外还展现出版写文原来科罚文本推理问题的后劲。
盘考发现视频生成模子还是Few-shot Learner;Self-consistency可进一步升迁视频生成推感性能。
举座来看,团队以为Thinking with Video为多模态推理开导了无尽可能。
论文连络:
https://arxiv.org/abs/2511.04570
样式网站:
https://thinking-with-video.github.io
代码仓库:
https://github.com/tongjingqi/Thinking-with-Video
数据集:
https://huggingface.co/datasets/OpenMOSS-Team/VideoThinkBench
一键三连「点赞」「转发」「注意心」
宽宥在挑剔区留住你的思法!
— 完 —
咱们正在招聘又名眼疾手快、存眷AI的学术剪辑实习生🎓
感兴趣的小伙伴宽宥存眷 👉 了解深信

🌟 点亮星标 🌟
2026世界杯中国体彩官网入口科技前沿进展逐日见JRS直播2026世界杯赛事直播入口
 备案号:
备案号: